
Enabling pre-trained StyleGAN models to image-to-image translation
In addition to improving the model performance and quality, modern approaches also focus on manipulating the trained network to produce outputs that are diverse from the original dataset.
A previous study on StyleGAN Encoder [1] demonstrated a variety of facial image-to-image translation tasks, which encode real images into extended latent space W+.
Model Rewriting [2] showed that editing a network's internal rules allows us to map new elements to the generated image intentionally.
Network Bending [3] showed that the transformations of spatial activation maps in GANs could create meaningful manipulations in the generated images.
Both of these works indicated that the knowledge encoded in a deep neural network is semantically related to the spatial information in its feature maps. And manipulating this information can create results diverse from the original domain. Therefore, we asked:
Could we introduce an additional network to learn the spatial distribution of information in a specific layer in a trained GAN model?
And with this additional network, if we could directly generate feature maps from a given real image and create image-to-image translation?
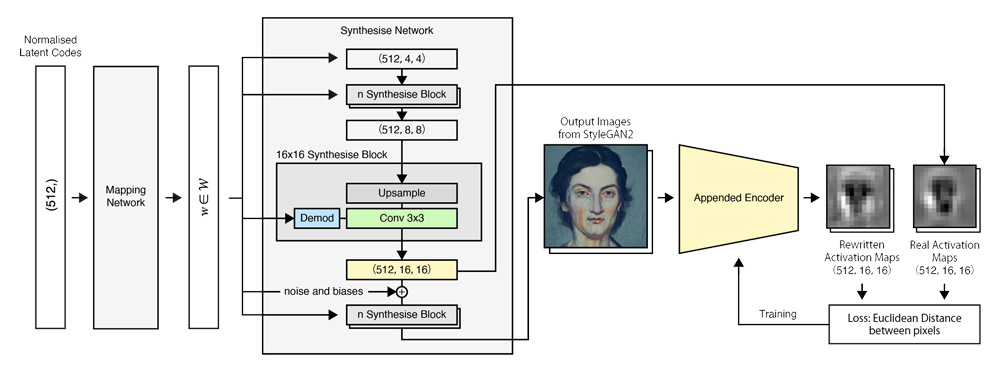
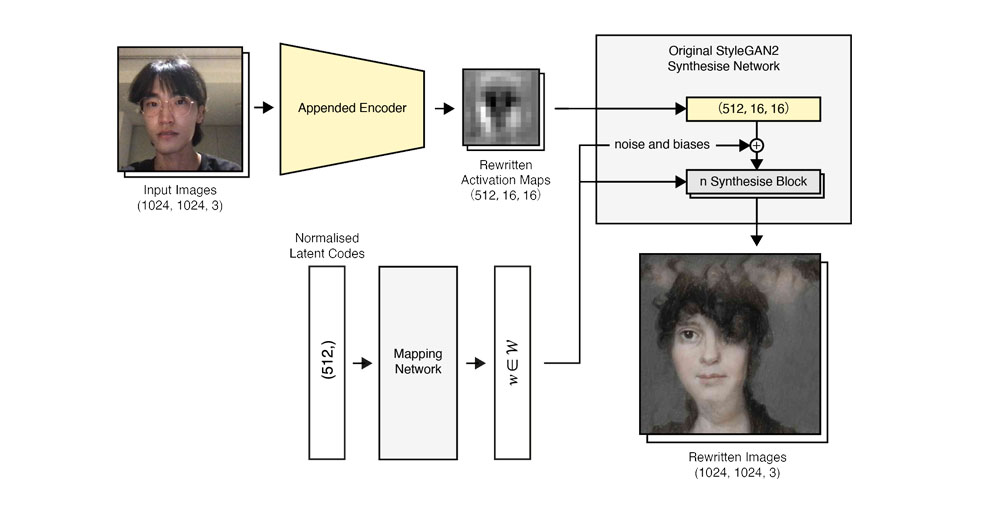
We proposed a training system appended to StyleGAN2 architecture, enabling a pre-trained StyleGAN2 model to perform image-to-image translation, even if the input images are not in the original domain. The training system is based on an encoder network that downscales the generated images from a StyleGAN2 model and matches the distribution of the earlier activation maps in the same model (i.e. predict feature maps given a generated image). After training, the encoder network is migrated to the StyleGAN2 model.
The proposed system was implemented on a couple of pre-trained models. And the results showed that it's able to create meaningful image-to-image translation different with pix2pixHD and other state-of-the-art image translation models.